
수퍼톤(대표 이교구)이 한국어 포함 31개 언어를 지원하는 차세대 음성합성 모델을 공개했다. 인터넷 연결 없이도 PC·모바일·브라우저·임베디드 기기에서 직접 실행할 수 있는 것이 특징이다.
수퍼톤은 15일(현지시간) 새로운 온디바이스 텍스트 음성 변환(TTS) 모델 ‘수퍼토닉 3(Supertonic 3)’를 공개했다.
이 모델은 깃허브를 통해 공개됐으며, 상업적 사용이 가능하다. 깃허브 트랜딩 차트에서 1위 인기 저장소에 올랐다.
수퍼토닉 3는 ONNX 기반으로 동작하는 경량 TTS 시스템으로, 서버 연결 없이 로컬 기기에서 음성을 생성할 수 있다. 수퍼톤은 “완전한 프라이버시 보호와 낮은 지연시간을 제공하는 CPU 중심 온디바이스 음성합성 모델”이라고 설명했다.
이번 버전은 지난해 11월 공개된 수퍼토닉 2 대비 언어 지원 범위가 크게 확대됐다. 이전 버전이 영어·한국어·스페인어·포르투갈어·프랑스어 등 5개 언어만 지원했던 것과 달리, 이번에는 일본어·독일어·아랍어·러시아어·터키어·베트남어 등 총 31개 언어를 지원한다.
특히 음성 생성 과정에서 자주 발생하던 단어 반복이나 문장 생략 오류를 줄이고, 발음 정확도와 화자 유사성도 개선했다. 슈퍼톤은 이를 통해 실제 제품 환경에서 안정성을 크게 높였다고 강조했다.
새롭게 추가된 기능 중 하나는 감정 표현 태그다. 사용자는 텍스트 안에 <laugh>, <breath>, <sigh>, <scream> 같은 태그를 직접 삽입해 웃음, 숨소리, 한숨 등의 감정 표현을 음성에 반영할 수 있다. 별도의 전처리 시스템 없이 텍스트만으로 감정과 호흡을 제어할 수 있어 음성 비서나 접근성 서비스 개발에 유용할 것으로 기대된다.
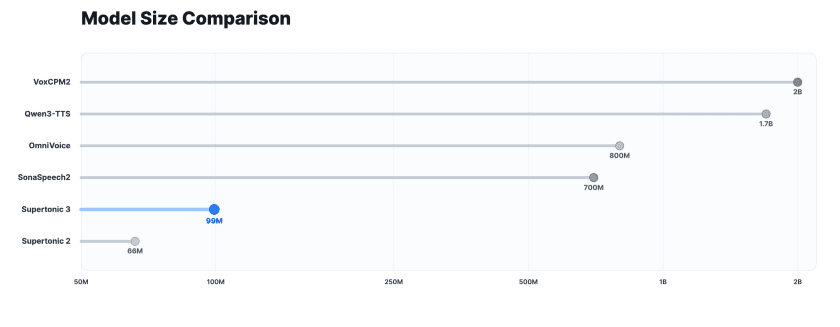
모델 규모는 약 9900만(99M) 매개변수 수준으로, 공개된 ONNX 자산 전체 크기는 약 404MB다. 이는 7억~20억 매개변수 규모의 대형 오픈소스 TTS 모델보다 훨씬 작은 수준이다. 다운로드 용량과 메모리 사용량, 실행 속도 측면에서 장점이 있다.
실제로 수퍼토닉 3는 GPU 없이 CPU만으로도 빠르게 동작하도록 설계됐다. 전자잉크 리더기인 '오닉스 부크스 고 6(Onyx Boox Go 6)'에서도 비행기 모드 상태로 실시간에 가까운 음성 생성 성능을 구현했다. 브라우저 환경에서는 onnxruntime-web 기반으로 순수 클라이언트 실행이 가능하며, 모바일과 라즈베리파이 같은 저전력 장치에서도 동작한다.
또 하나의 강점은 텍스트 정규화(Text Normalization) 기능이다. 일반 TTS 시스템은 금액, 날짜, 전화번호, 단위 표기 등을 자연스럽게 읽기 위해 별도 전처리 과정을 요구하는 경우가 많다. 그러나 수퍼토닉 3는 “$5.2M”을 “520만달러”, “30kph”를 “시속 30킬로미터”처럼 자연스럽게 변환해 읽을 수 있다고 설명했다.
경쟁 모델들과 비교한 테스트에서 '오픈AI TTS-1', '제미나이 2.5 플래시 TTS', 마이크로소프트, 일레븐랩스 등의 시스템이 일부 금융·단위 표현에서 오류를 보였지만, 수퍼토닉 3는 이를 정확하게 처리했다고 주장했다.
기술적으로는 음성 오토인코더와 플로우 매칭(Flow Matching) 기반 생성 구조를 유지하면서, LARoPE(Length-Aware Rotary Position Embedding)와 자체 정화 플로우 매칭(Self-Purifying Flow Matching) 기법을 추가해 텍스트와 음성의 정렬 정확도를 높였다. 덕분에 단 2번의 추론 단계만으로도 자연스러운 음성을 생성할 수 있다는 설명이다.
또 최근 공개한 ‘보이스 빌더(Voice Builder)’를 통해 개발자들이 자신의 음성을 기반으로 맞춤형 TTS 모델을 제작할 수 있도록 지원하고 있다.
박찬 기자 cpark@aitimes.com