AI의 성능을 인간의 IQ처럼 수치화해 비교하는 새로운 평가 프로젝트가 등장해 화제다. AI 모델의 복잡한 능력을 직관적으로 비교할 수 있다는 호평과 동시에 “AI를 단일 숫자로 환원하는 것은 위험한 착시”라는 비판이 동시에 제기되고 있다.
엔지니어 겸 투자자인 라이언 셰이는 14일(현지시간) 인간의 지능을 측정하는 IQ 테스트처럼 AI 지능을 측정하는 ‘ AI IQ’를 공개했다.
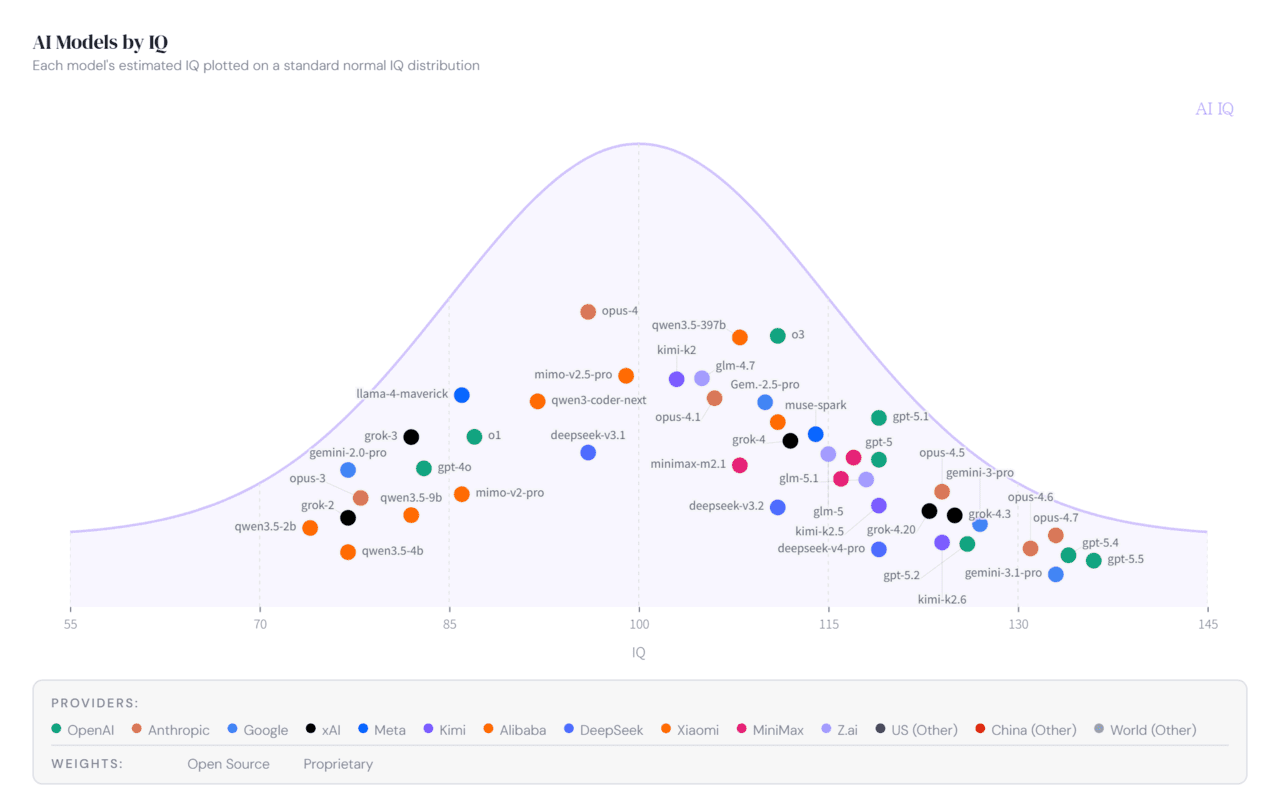
AI IQ는 50개 이상의 주요 대형언어모델(LLM)에 인간식 IQ 개념을 적용해 점수를 부여하고 이를 시각화한 것이다. AI 모델들의 추론 능력과 비용 효율성, 감성 지능(EQ)까지 비교할 수 있도록 구성돼 있다.
12개의 벤치마크를 기반으로 모델 성능을 평가한다. 평가 항목은 ▲추상 추론 ▲수학 추론 ▲프로그래밍 추론 ▲학술 추론 등 4가지 영역으로 나뉜다. 여기에는 'ARC-AGI' '프론티어매스' 'SWE-벤치' '인류의 마지막 시험(HLE)' 같은 최신 벤치마크들이 포함됐다.
각 벤치마크 결과는 ‘난이도 기반 수동 보정 곡선(hand-calibrated difficulty curves)’을 통해 인간 IQ와 유사한 값으로 환산된다. 또 데이터 오염 가능성이 높거나 비교적 쉬운 벤치마크는 점수 상한을 제한해 과대평가를 막도록 설계됐다.
오픈AI의 'GPT-5.5'가 136 수준의 추정 IQ를 기록하며 현재 1위를 차지했다. ▲앤트로픽의 '클로드 오퍼스 4.7(IQ 132)' ▲'GPT-5.4' ▲구글의 '제미나이 3.1 프로(이상 IQ 131)'이 뒤를 잇고 있다.
이처럼 최상위 모델 간 격차는 그리 크지 않다. 전문가들은 이를 AI 성능 상향 평준화로 해석하고 있다.
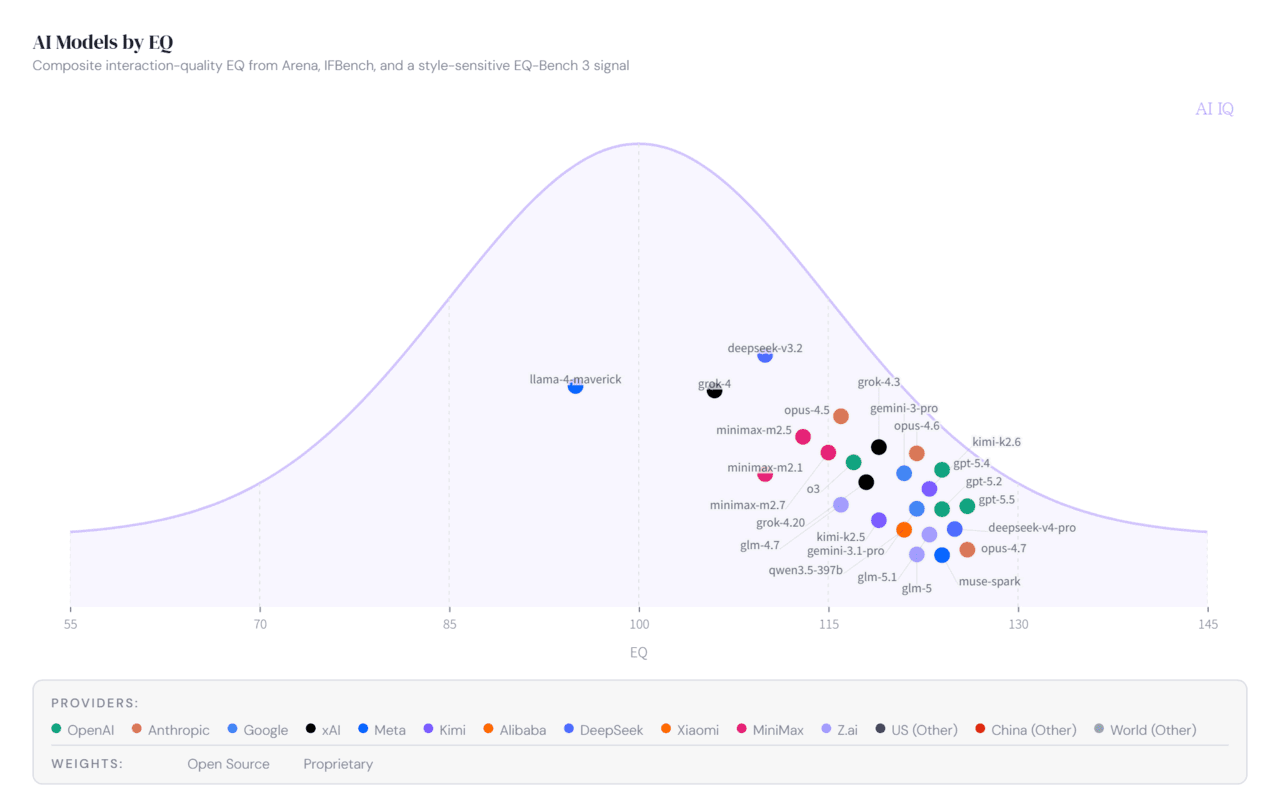
특히, AI IQ 프로젝트는 IQ뿐 아니라 ‘EQ(감성 지능)’ 개념까지 도입해 눈길을 모았다. EQ는 'EQ-벤치 3'와 '아레나 Elo' 점수를 기반으로 계산된다.
이 평가에서는 앤트로픽의 클로드 오퍼스 4.7이 가장 높은 EQ 점수를 기록, ‘높은 지능과 높은 감성’을 동시에 갖춘 모델로 평가됐다. GPT-5.5는 IQ는 가장 높았지만 EQ에서는 다소 낮은 평가를 받았다.
하지만 EQ 평가 방식은 논란이 됐다. EQ-벤치 3가 앤트로픽의 클로드 모델을 기반으로 평가되기 때문이다. AI IQ 측은 이를 인정하며 앤트로픽 모델들에 200점의 Elo 페널티를 적용했다고 설명했다.
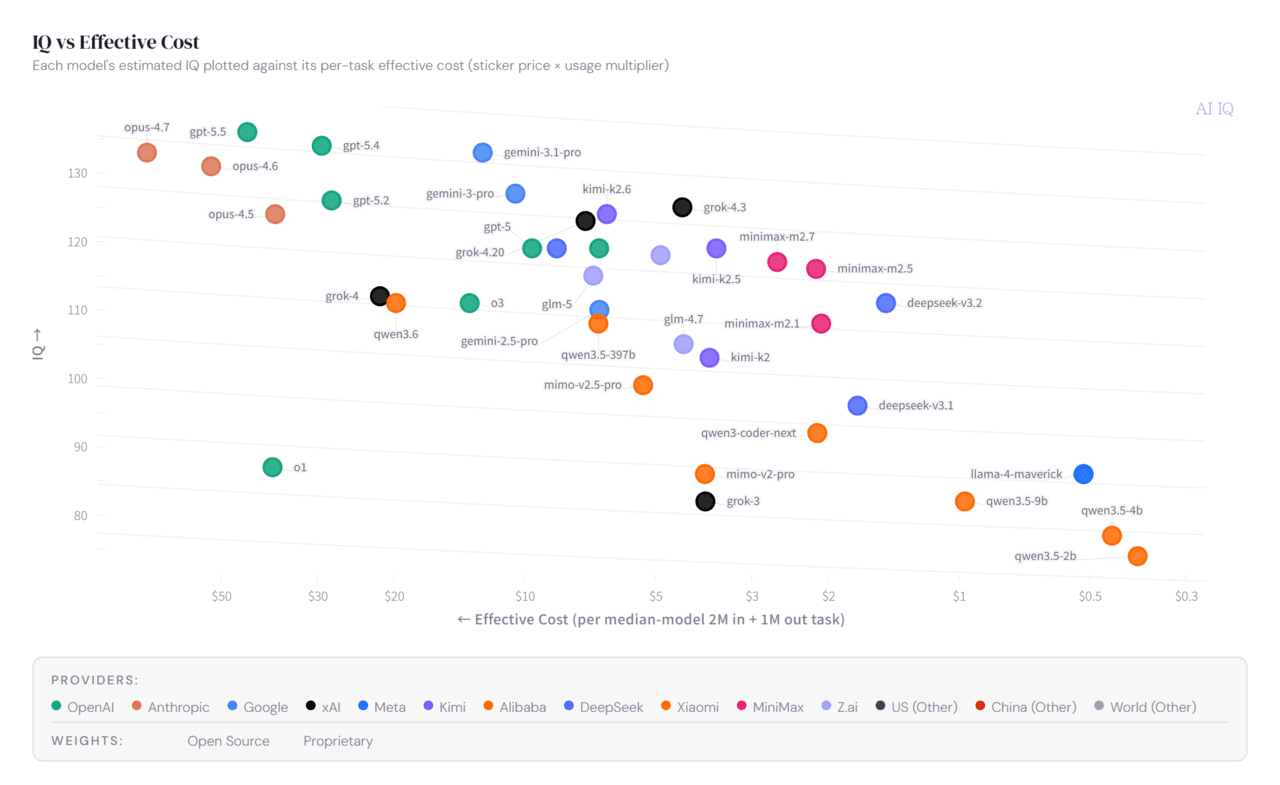
프로젝트의 또 다른 핵심 기능은 AI IQ와 비용을 동시에 비교하는 것이다. 이를 통해 기업은 운영 비용 대비 효율을 비교할 수 있다.
GPT-5.5와 클로드 오퍼스 4.7은 가장 높은 IQ를 기록했지만, 작업당 비용이 각각 30~50달러 이상으로 매우 높다. 'GPT-5.4-미니'와 '딥시크-V3.2' '미니맥스-M2.7' 등은 낮은 비용으로 준수한 성능을 제공하는 ‘가성비 모델’로 평가됐다.
업계에서는 이런 흐름이 앞으로 AI 운영 구조를 바꿀 수 있다고 보고 있다. 최고 성능 모델 하나만 사용하는 대신, 어려운 작업에는 고성능 모델을 쓰고 단순 업무에는 저렴한 모델을 배치하는 ‘라우팅 전략’이 핵심 경쟁력이 될 수 있다는 것이다.
그러나 AI IQ 프로젝트에 대한 비판도 거세다. 가장 큰 논란은 AI의 능력을 단일 숫자로 환원하는 접근 자체다.
일부 연구자들은 AI 모델이 특정 분야에서는 인간 전문가 수준 성능을 보이면서도, 어린아이 수준의 단순 문제에서는 실패하는 ‘들쭉날쭉한(jagged)’ 특성을 가진다고 지적한다. 이런 상황에서 인간 IQ를 인용하는 것은 오해의 소지가 크다는 지적이다.
프로젝트의 계산 방식이 완전히 공개되지 않았다는 점도 비판받고 있다. 사용된 벤치마크 목록과 보정 곡선 형태는 공개됐지만, 정확한 수학적 변환 과정과 원시 데이터는 공개되지 않았다.
일부 전문가들은 인간용 멘사(Mensa) 테스트를 AI에 그대로 적용하는 방식이 더 적절할 수 있다고 주장하기도 한다. 실제로 일부 프로젝트는 AI 모델에게 멘사 노르웨이 IQ 테스트를 직접 풀게 하고 있다.
그럼에도 일부 전문가는 AI IQ의 실용적 의미를 높게 평가하는 분위기다. 현재 AI 시장에는 미국·중국·유럽을 포함해 14개 이상의 주요 기업이 수십 종의 모델을 경쟁적으로 출시하고 있으며, 각 기업이 서로 다른 벤치마크를 사용해 성능을 홍보하고 있다.
이 가운데, AI IQ는 완벽하지 않더라도 서로 다른 모델을 하나의 프레임 안에서 비교할 수 있는 기준을 제시했다는 평가를 받고 있다.
특히 2023년 말 'GPT-4 터보'가 IQ 75 수준으로 평가됐던 것과 비교하면, 현재 최상위 모델들이 135 수준까지 도달했다는 점은 AI 발전 속도가 얼마나 빠른지를 보여준다는 평이다.
30개월 만에 첨단 모델의 IQ가 60포인트 가깝게 향상된 것이다.
박찬 기자 cpark@aitimes.com